





Scenes in the real world are often composed of several static and dynamic objects. Capturing their 4-dimensional structures, composition and spatio-temporal configuration in-the-wild, though extremely interesting, is equally hard. Therefore, existing works often focus on one object at a time, while relying on some category-specific parametric shape model for dynamic objects. This can lead to inconsistent scene configurations, in addition to being limited to the modeled object categories. We propose COM4D (Compositional 4D), a method that consistently and jointly predicts the structure and spatio-temporal configuration of 4D/3D objects using only static multi-object or dynamic single object supervision. We achieve this by a carefully designed training of spatial and temporal attentions on 2D video input. The training is disentangled into learning from object compositions on the one hand, and single object dynamics throughout the video on the other, thus completely avoiding reliance on 4D compositional training data. At inference time, our proposed attention mixing mechanism combines these independently learned attentions, without requiring any 4D composition examples. By alternating between spatial and temporal reasoning, COM4D reconstructs complete and persistent 4D scenes with multiple interacting objects directly from monocular videos. Furthermore, COM4D provides state-of-the-art results in existing separate problems of 4D object and composed 3D reconstruction despite being purely data-driven.
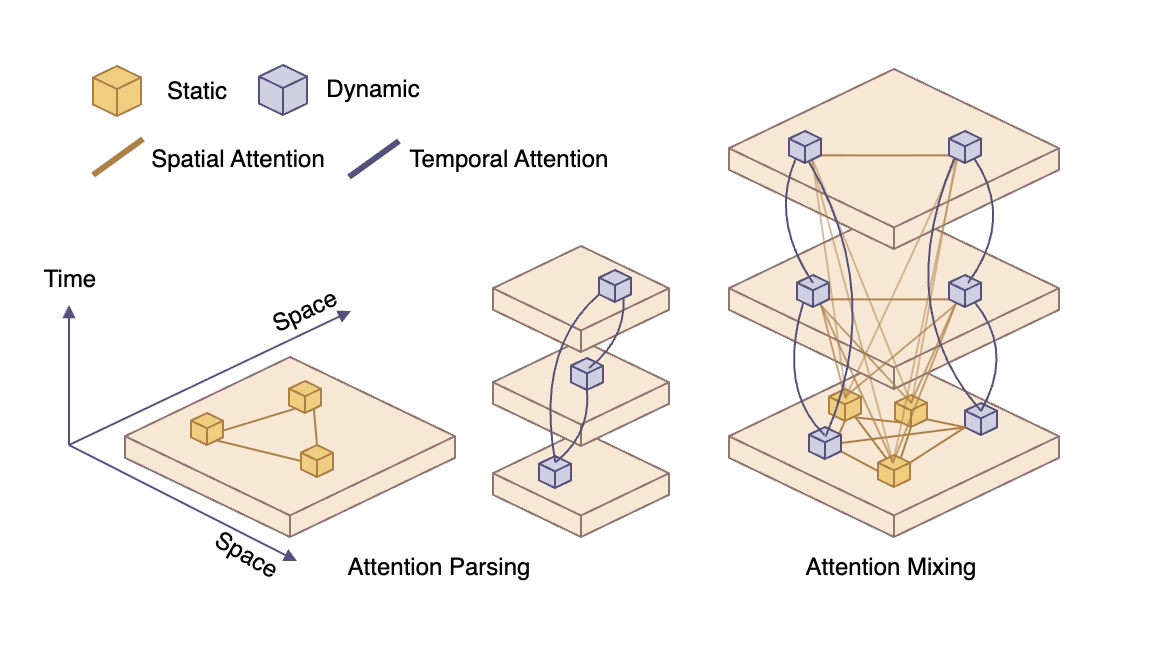
We assume scenes can be factored into static and dynamic components; separate priors for each guide compositional 4D reconstruction and keep the learned representation well-behaved even without fully observed 4D supervision.
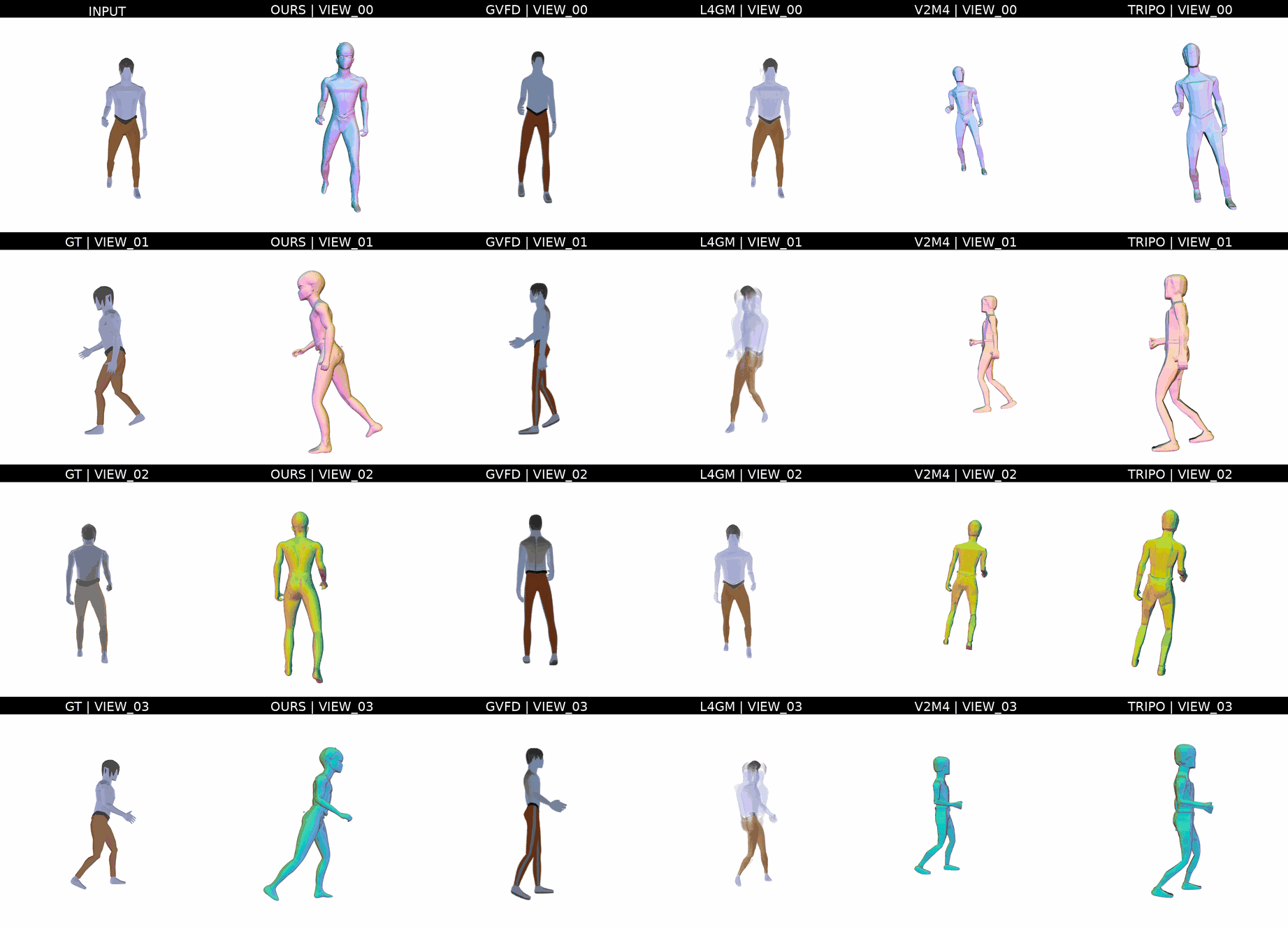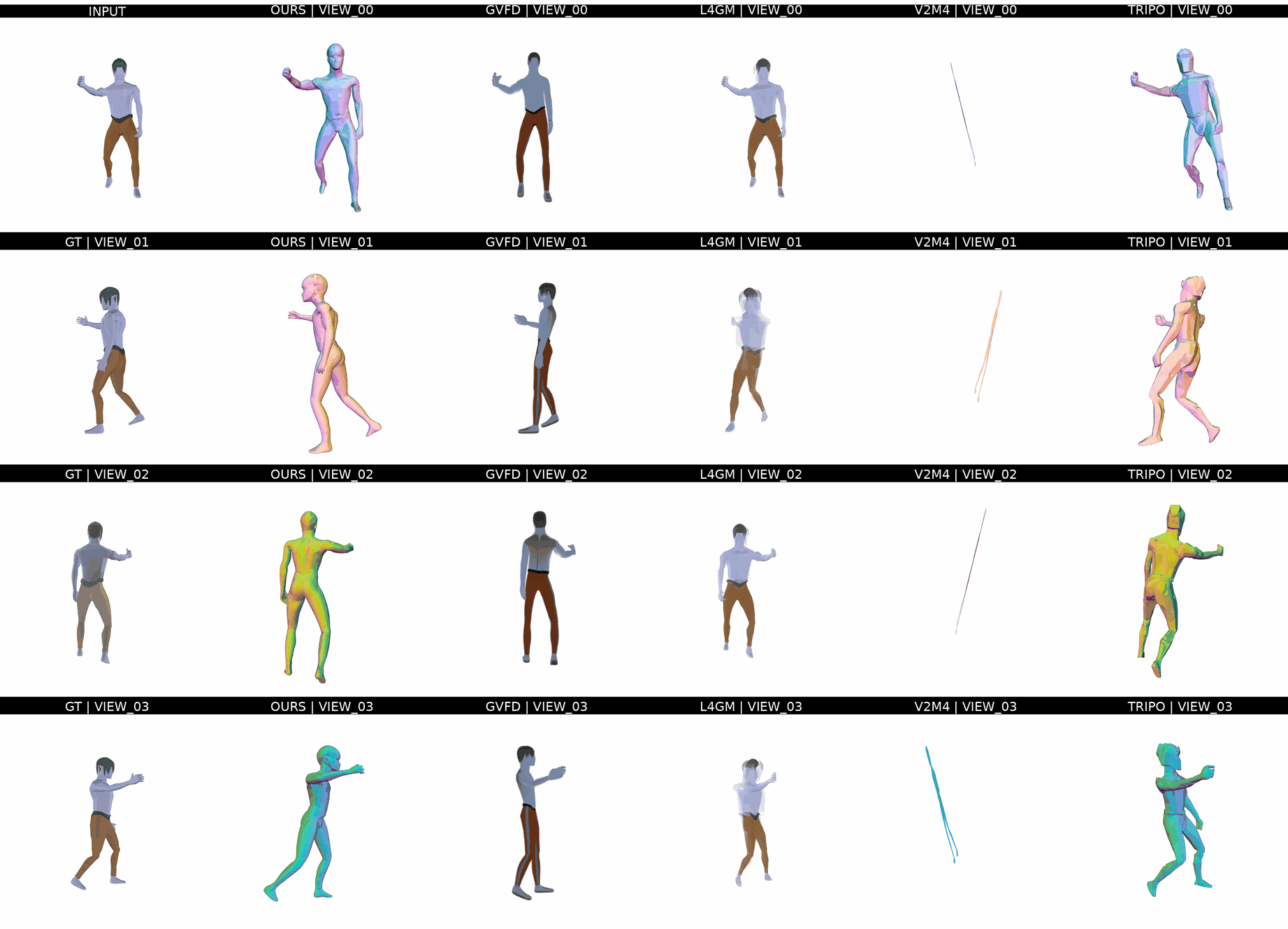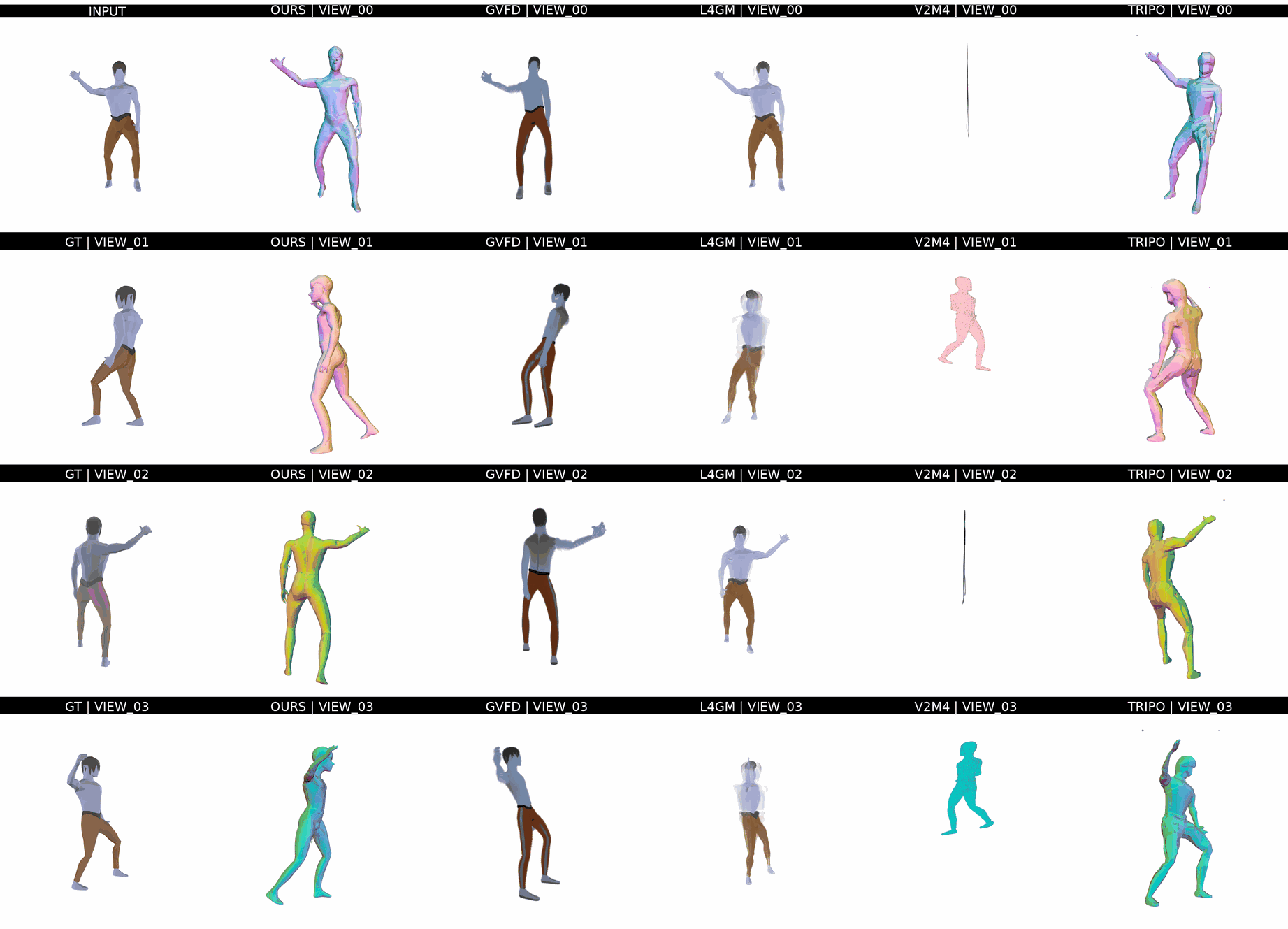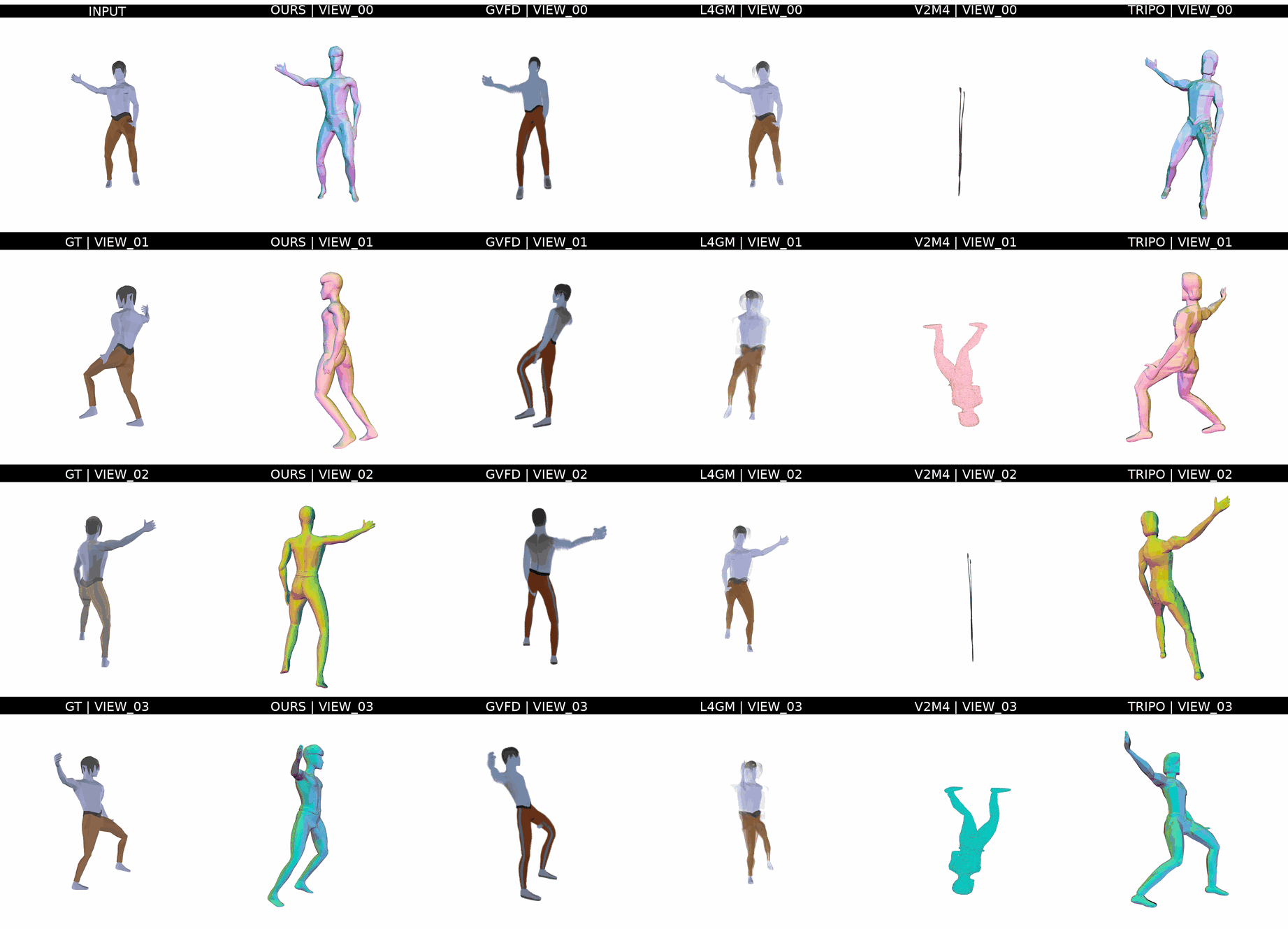
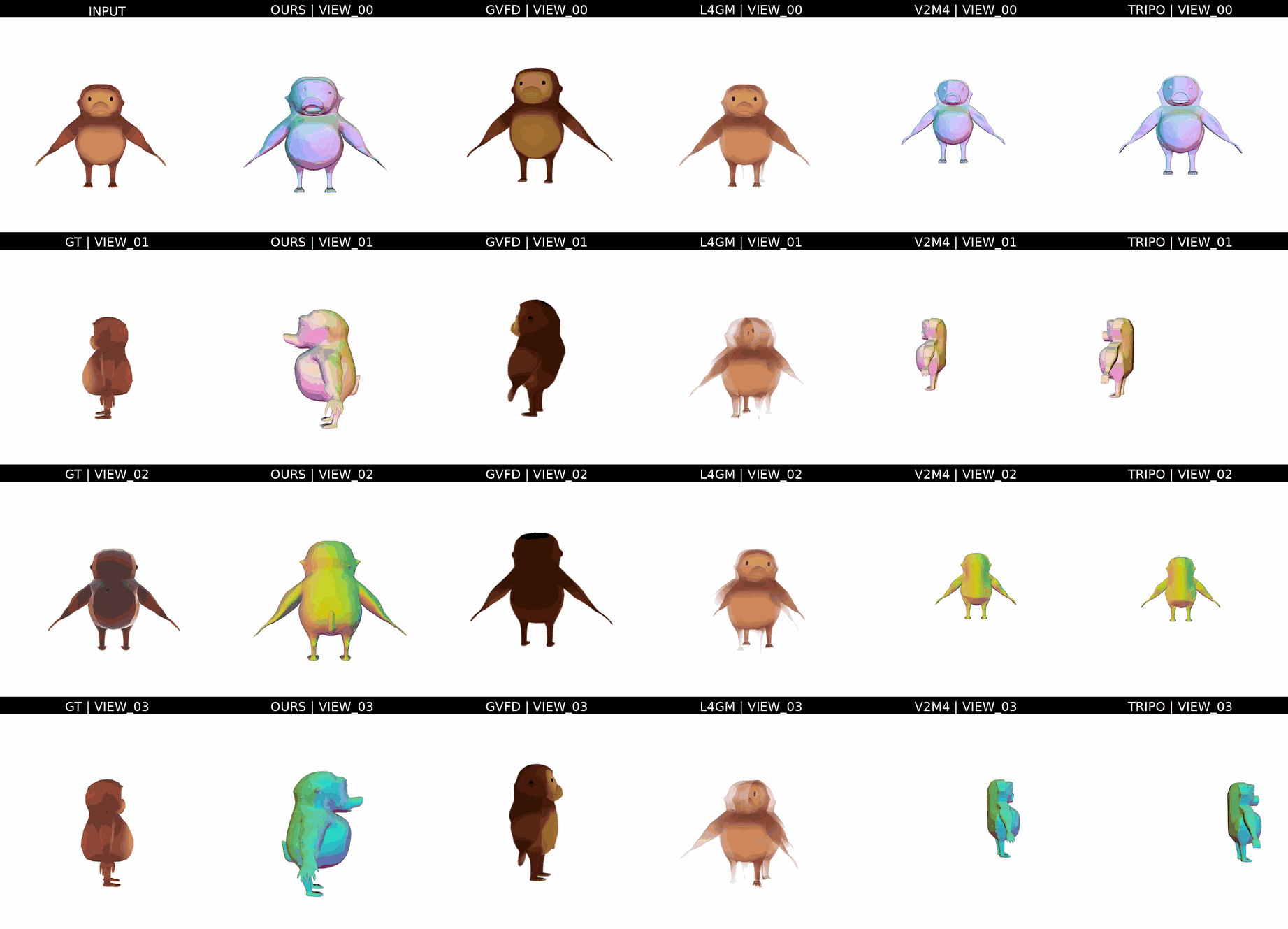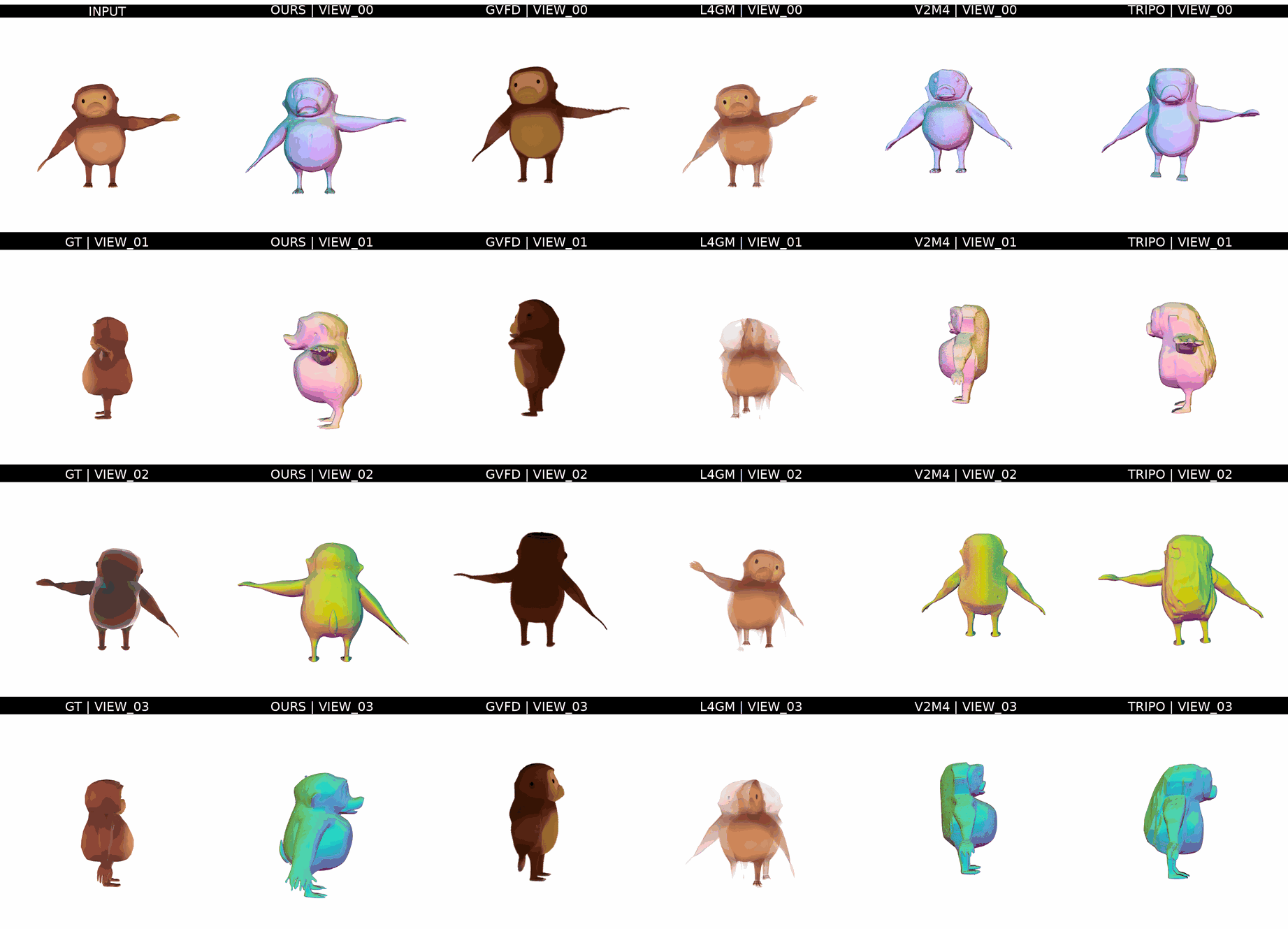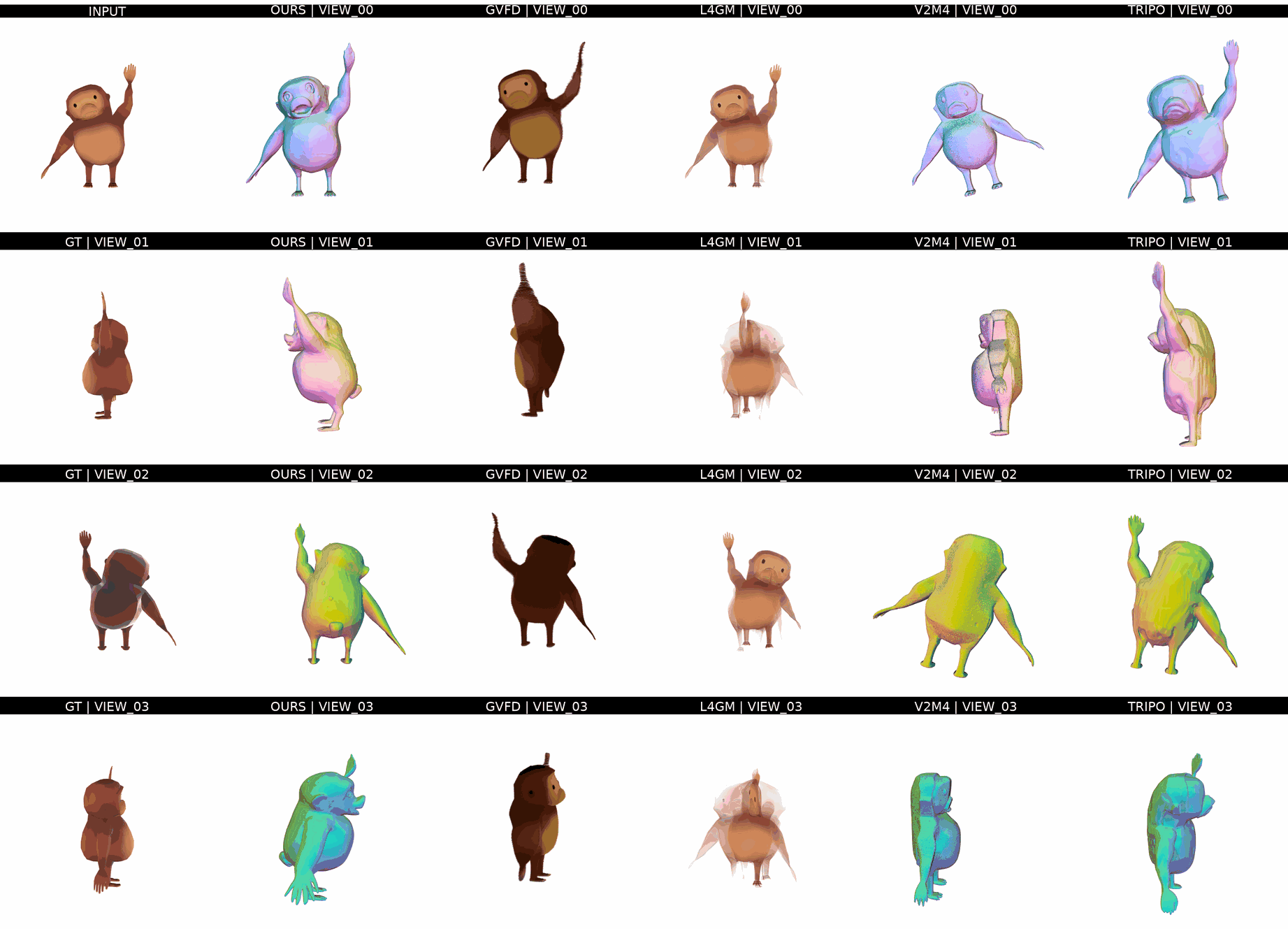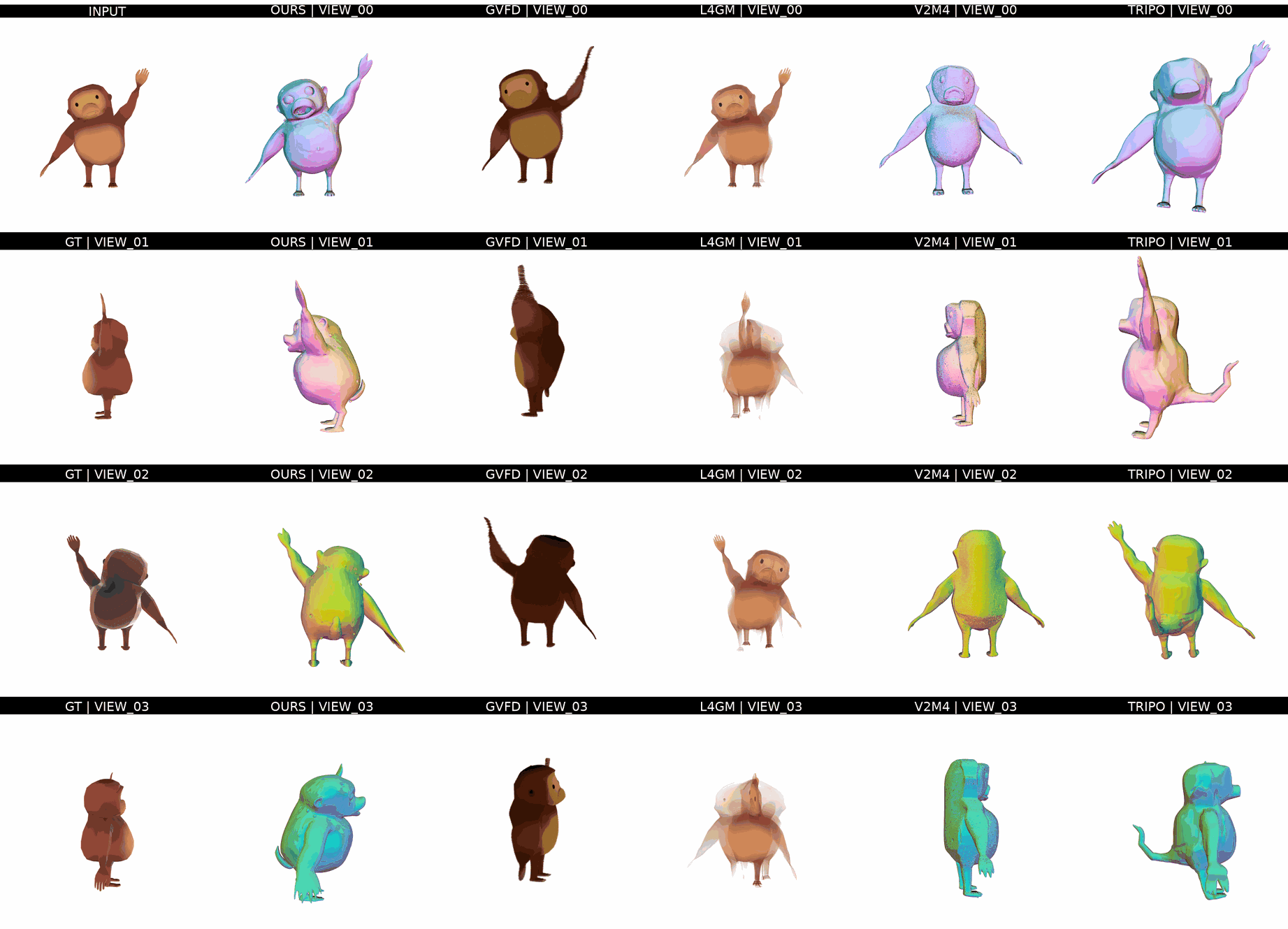
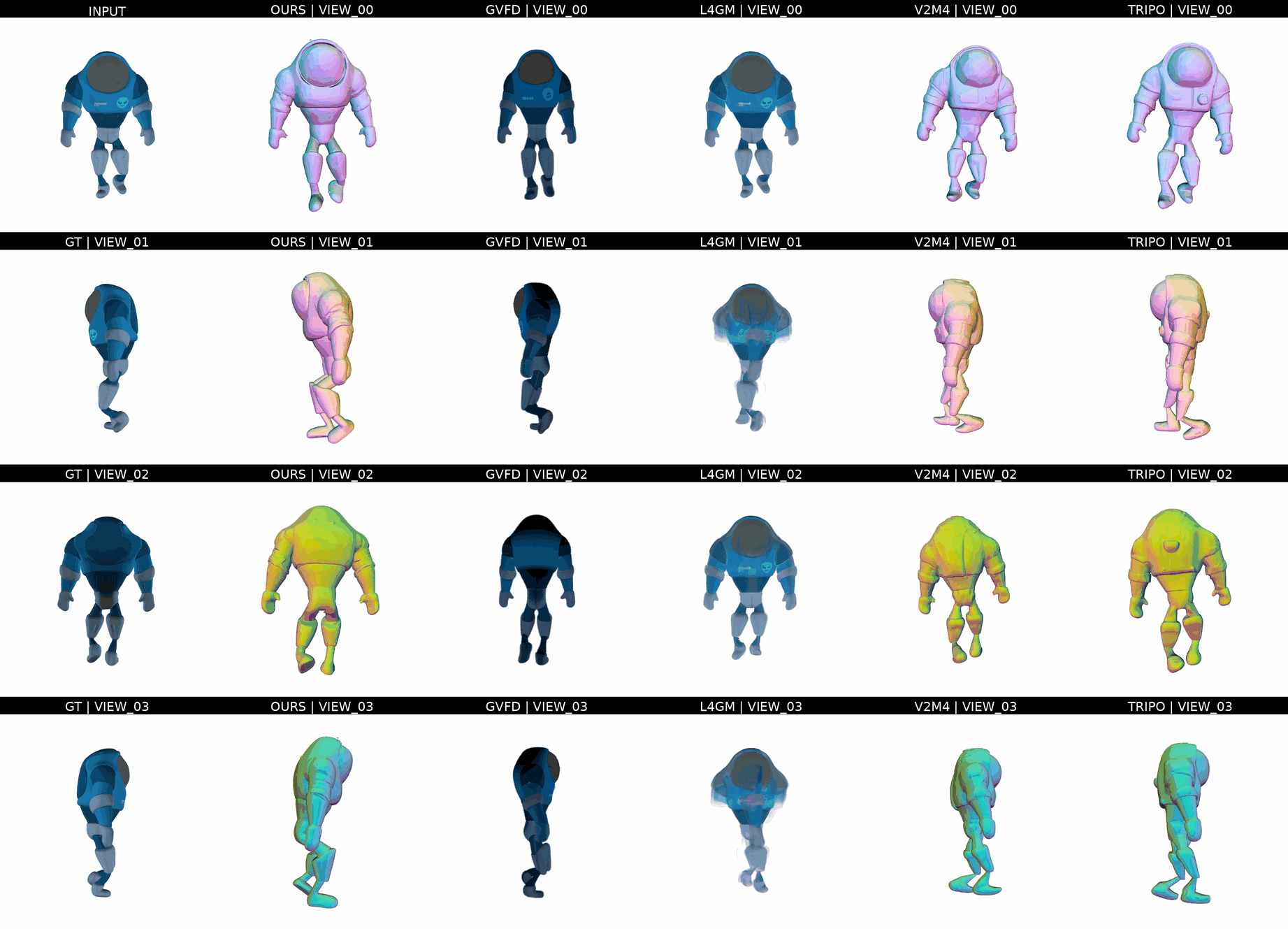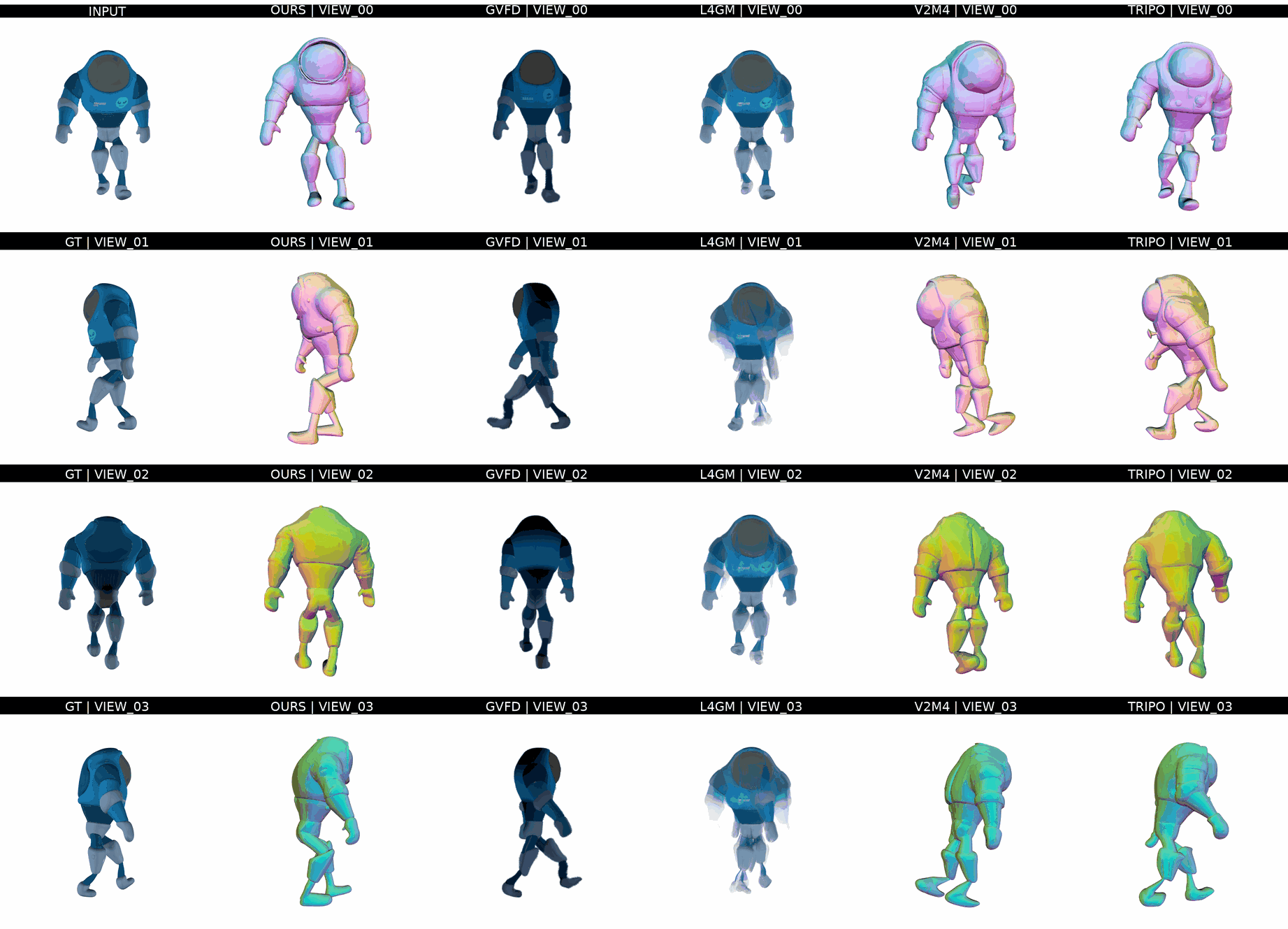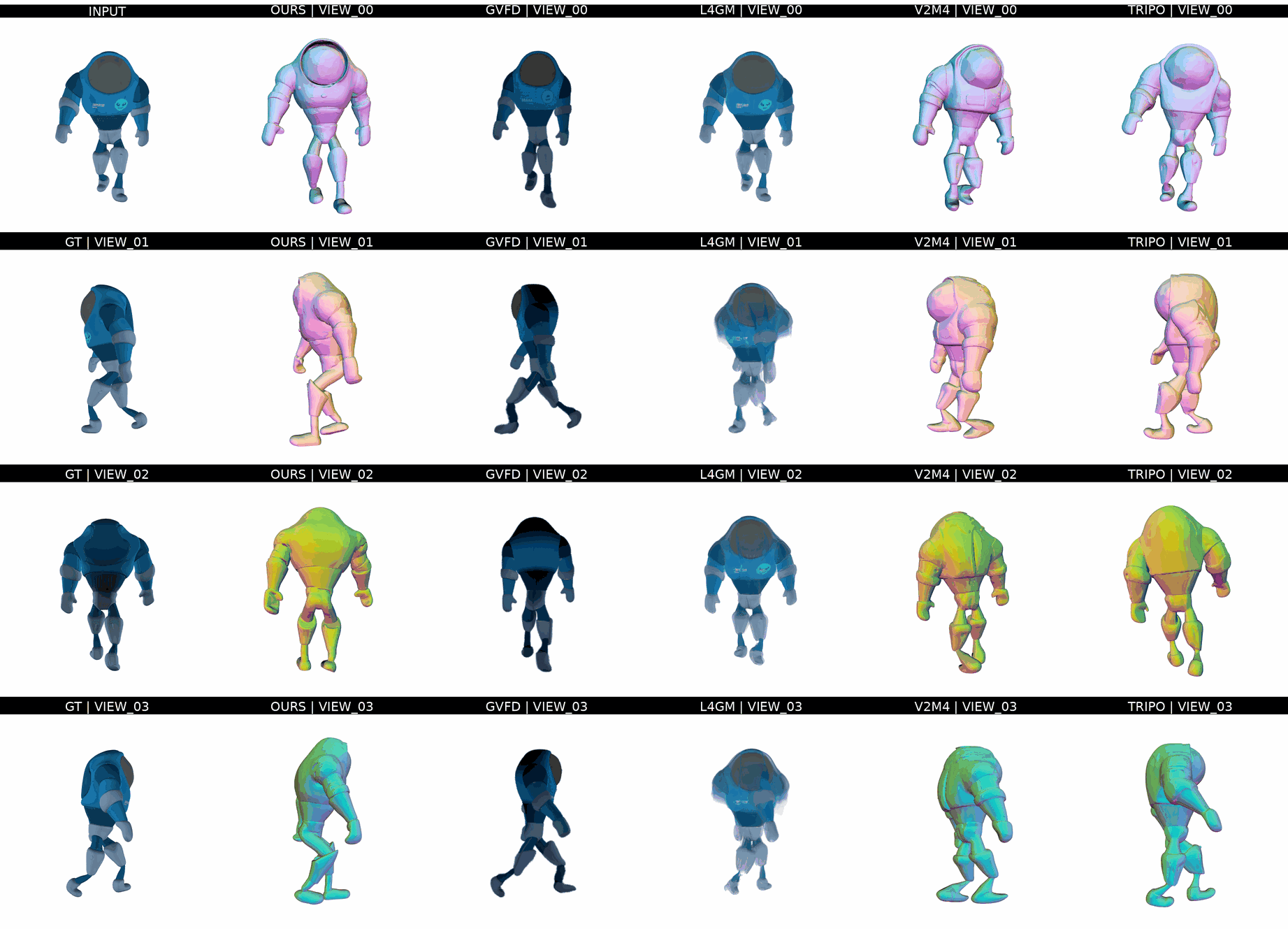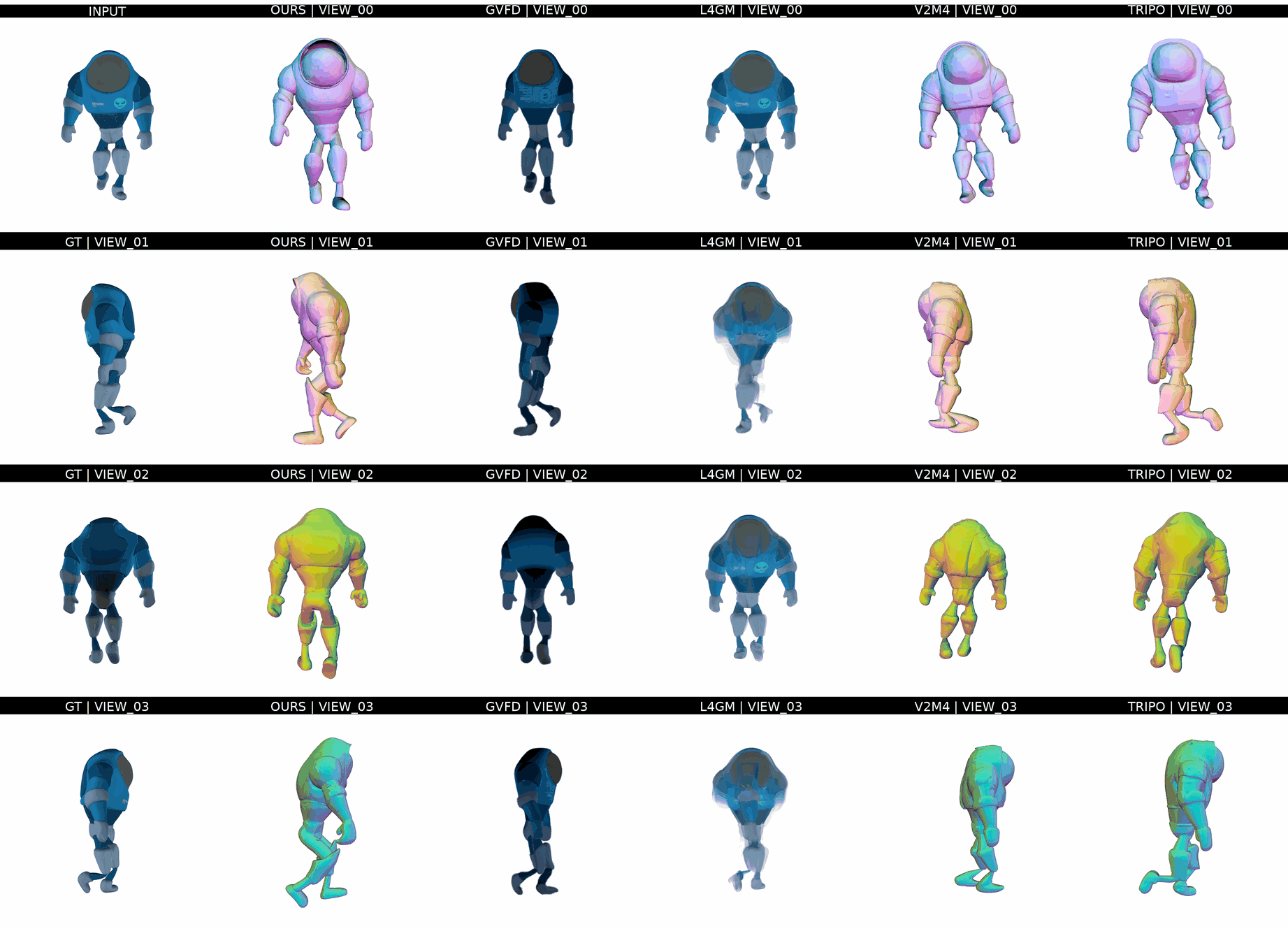
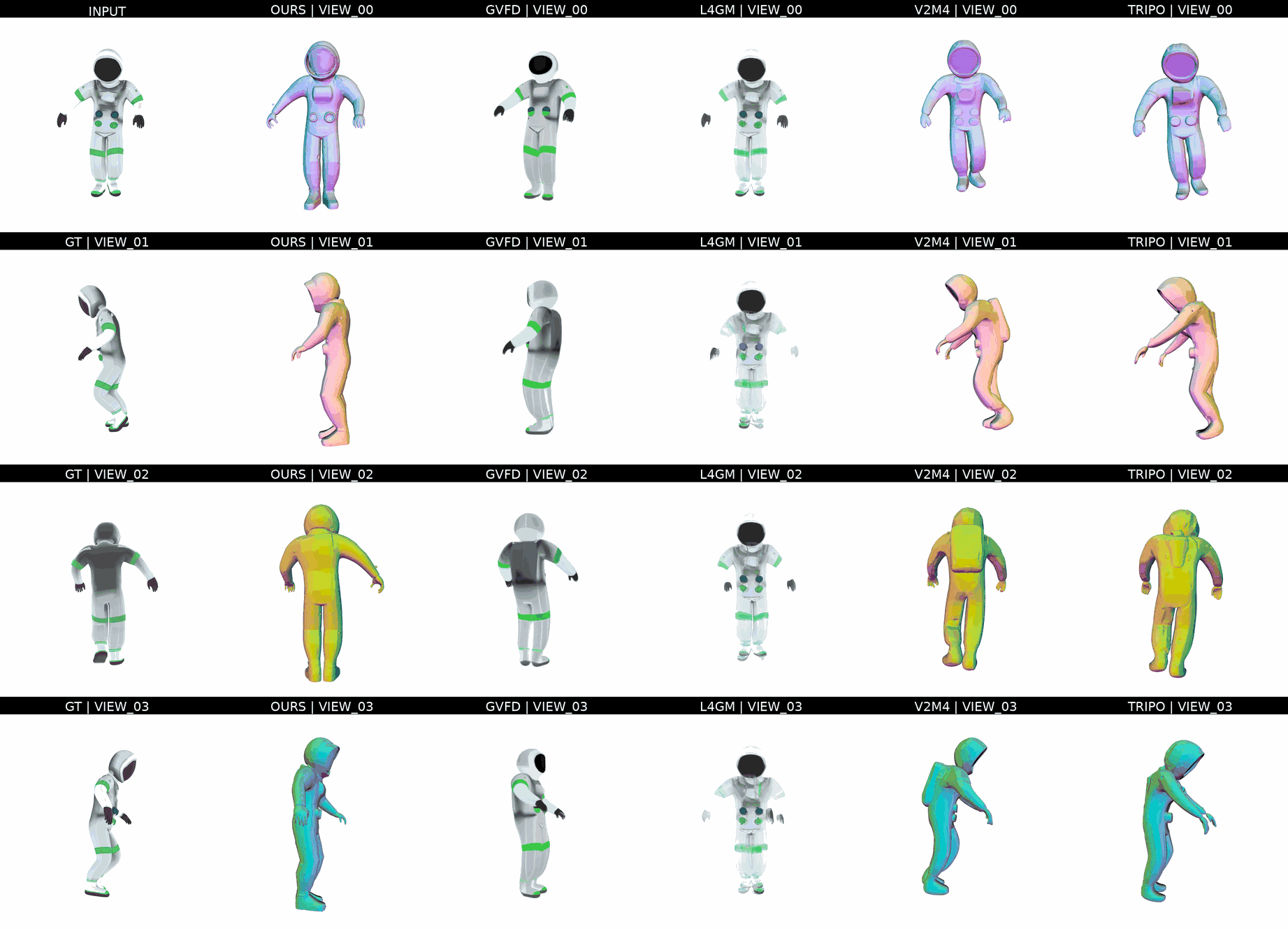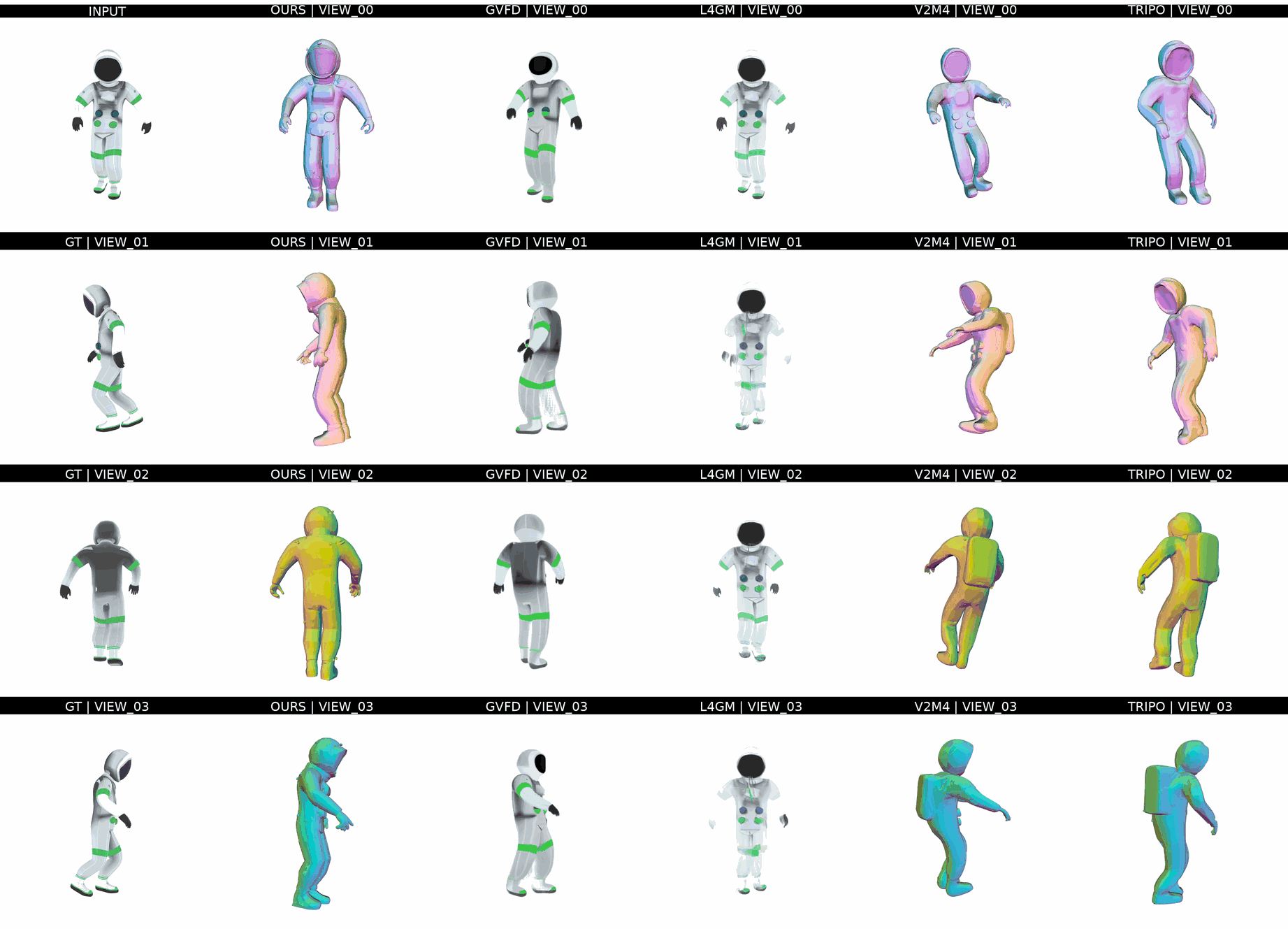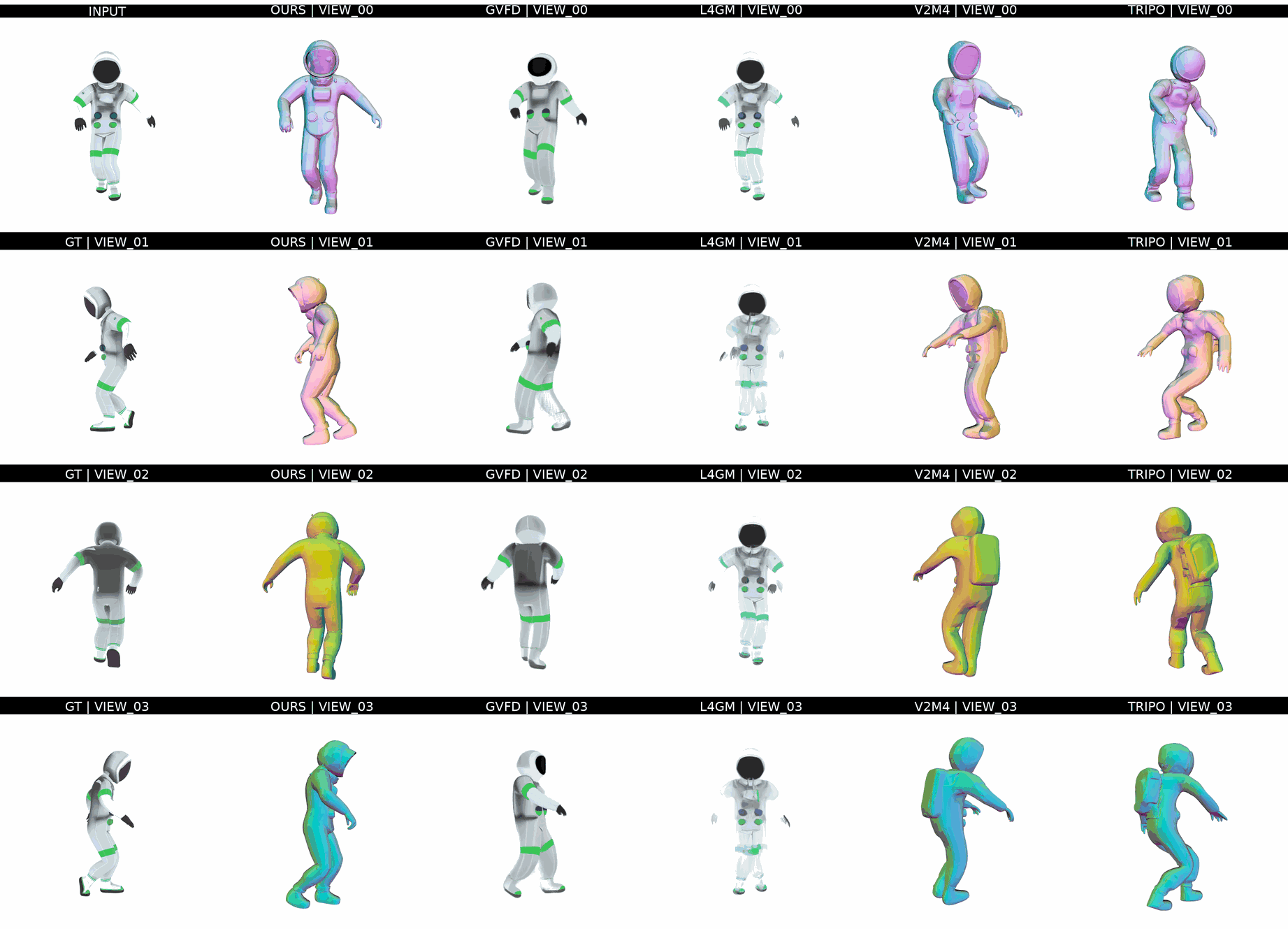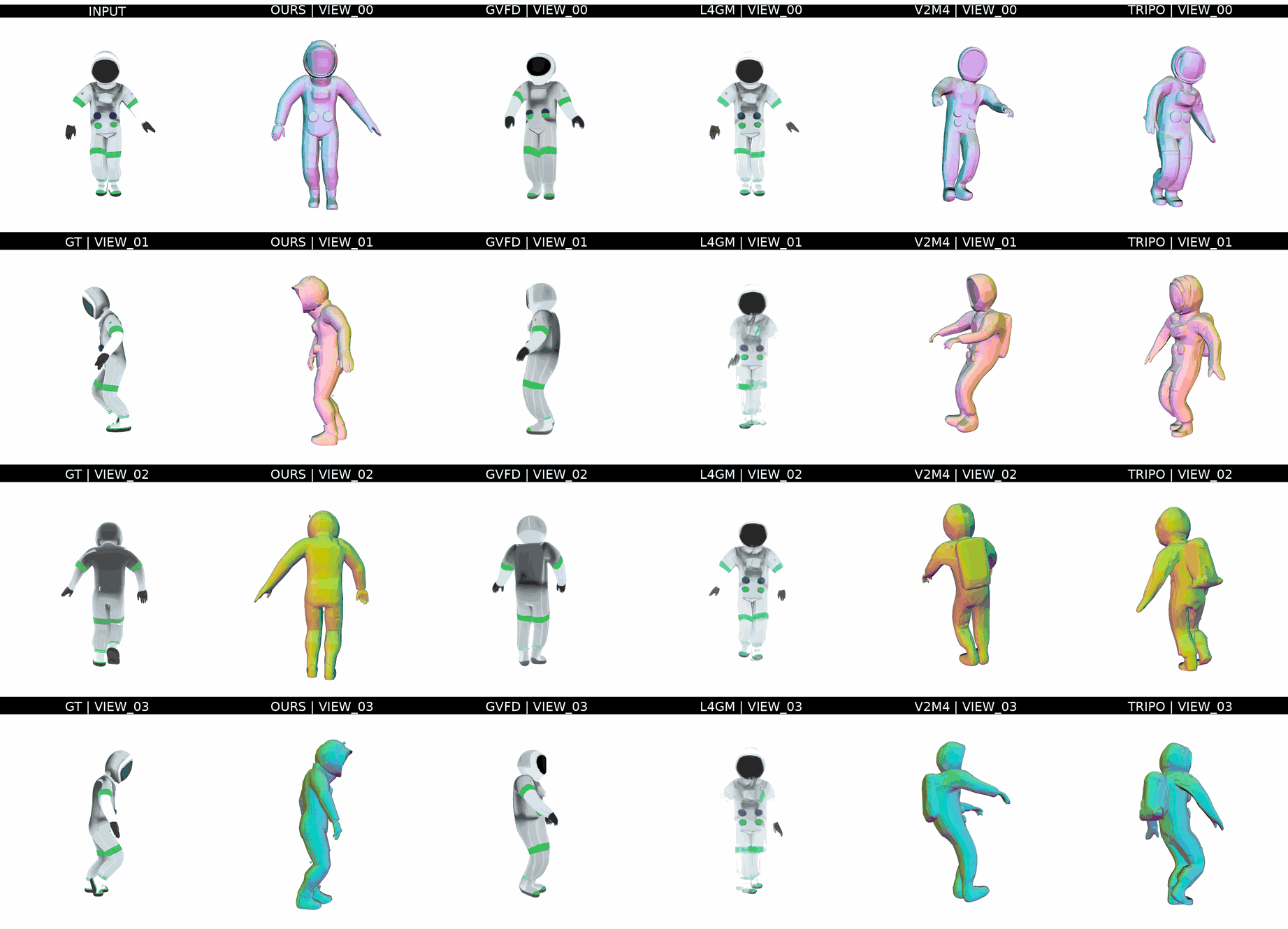
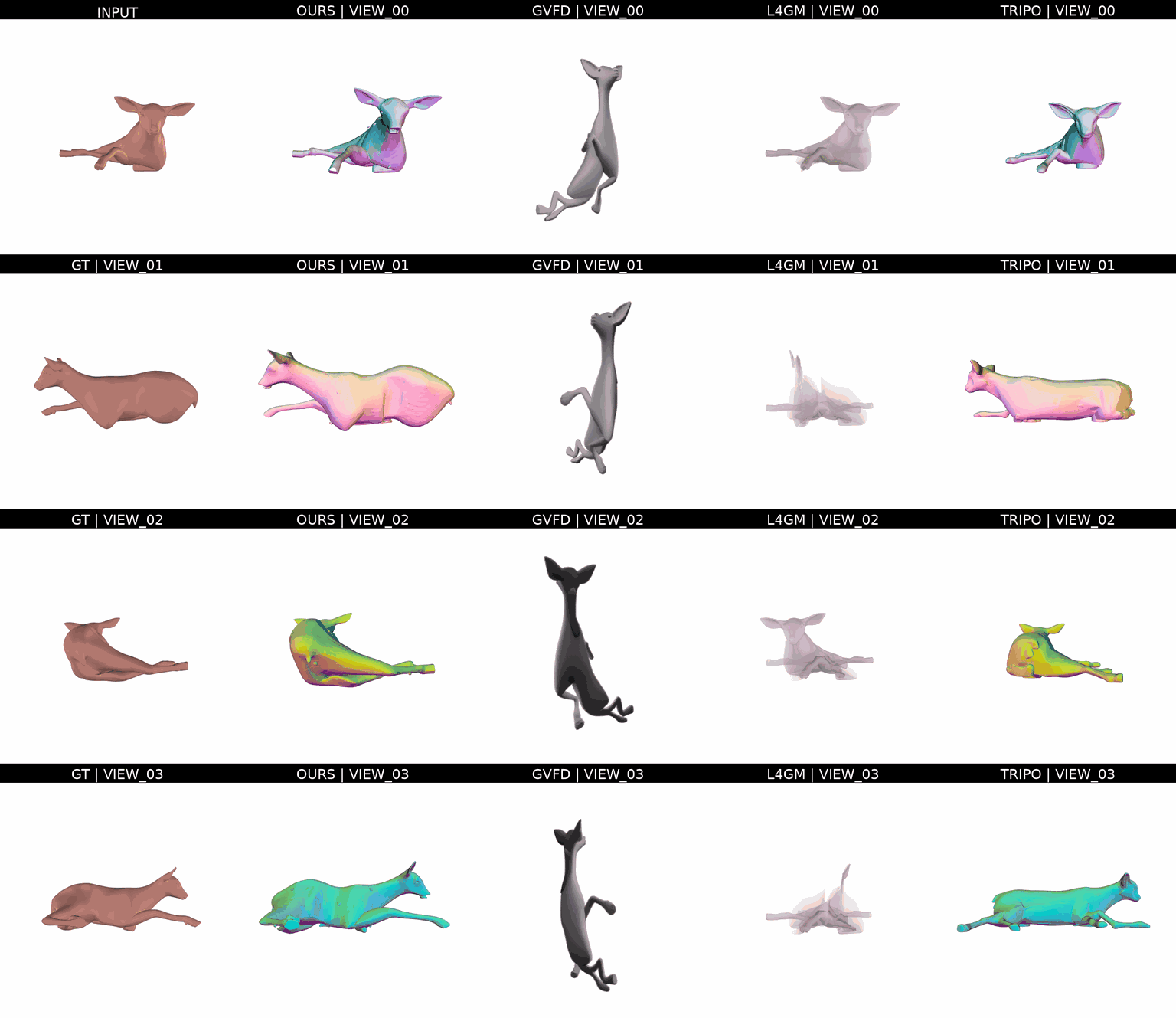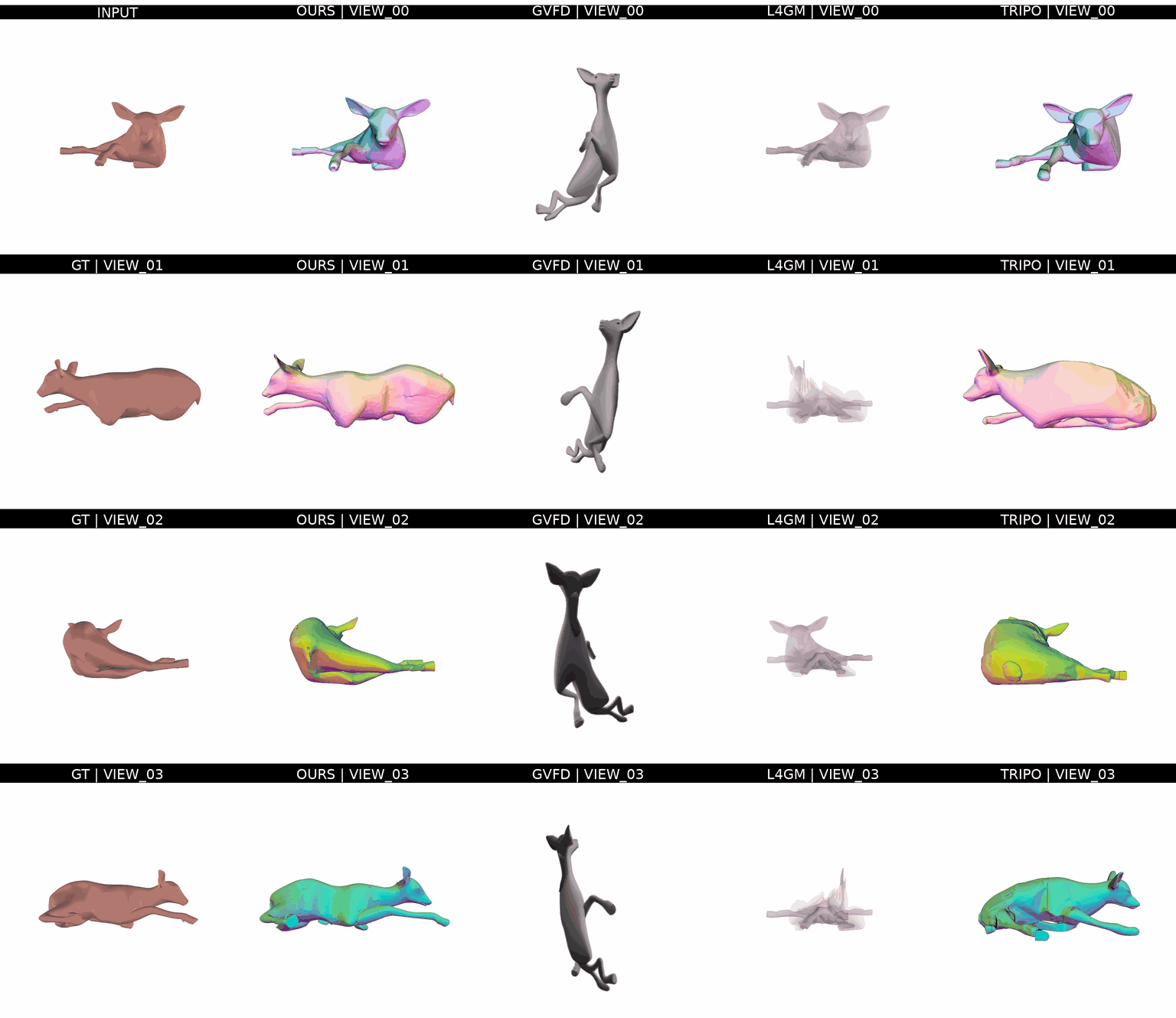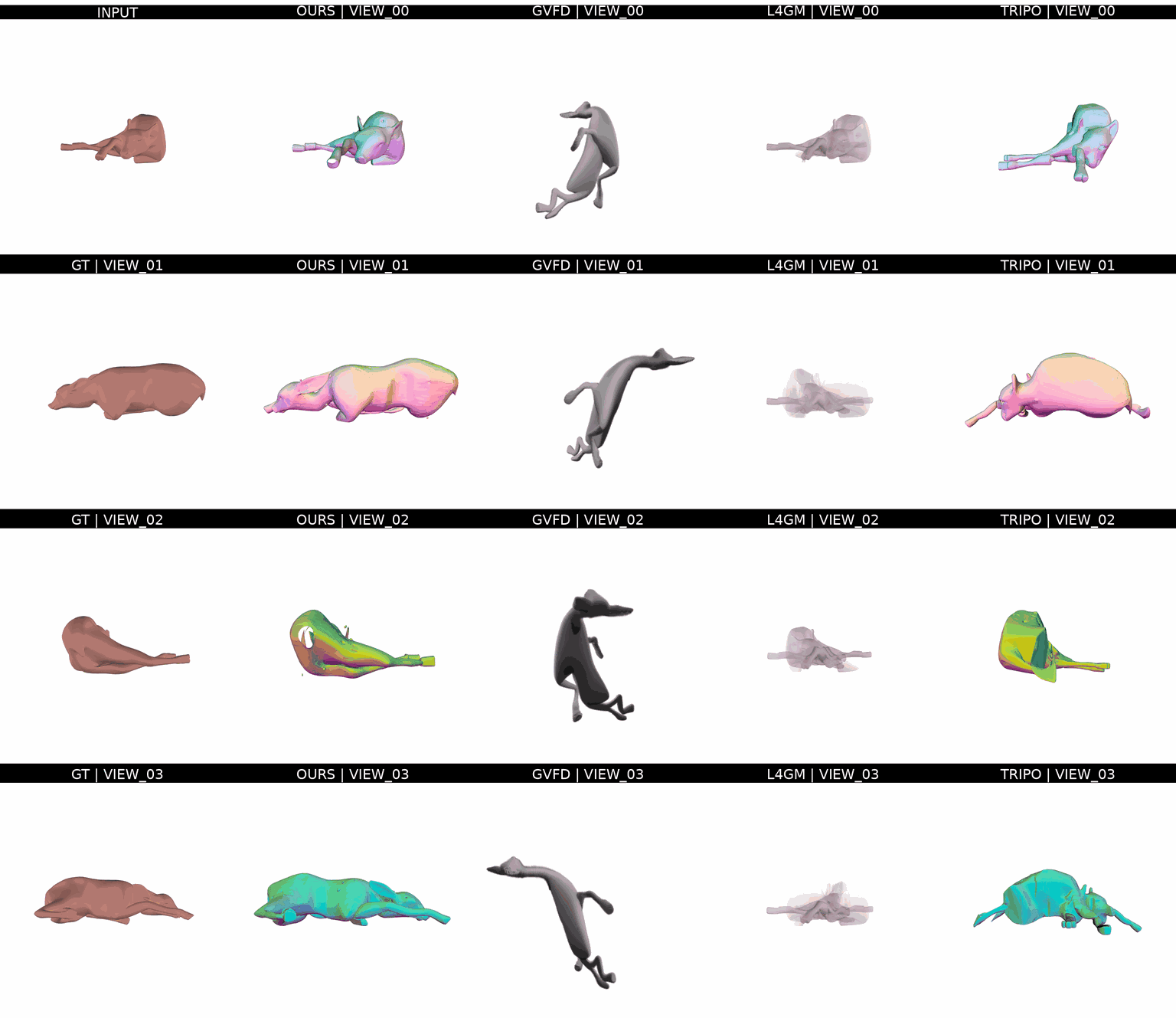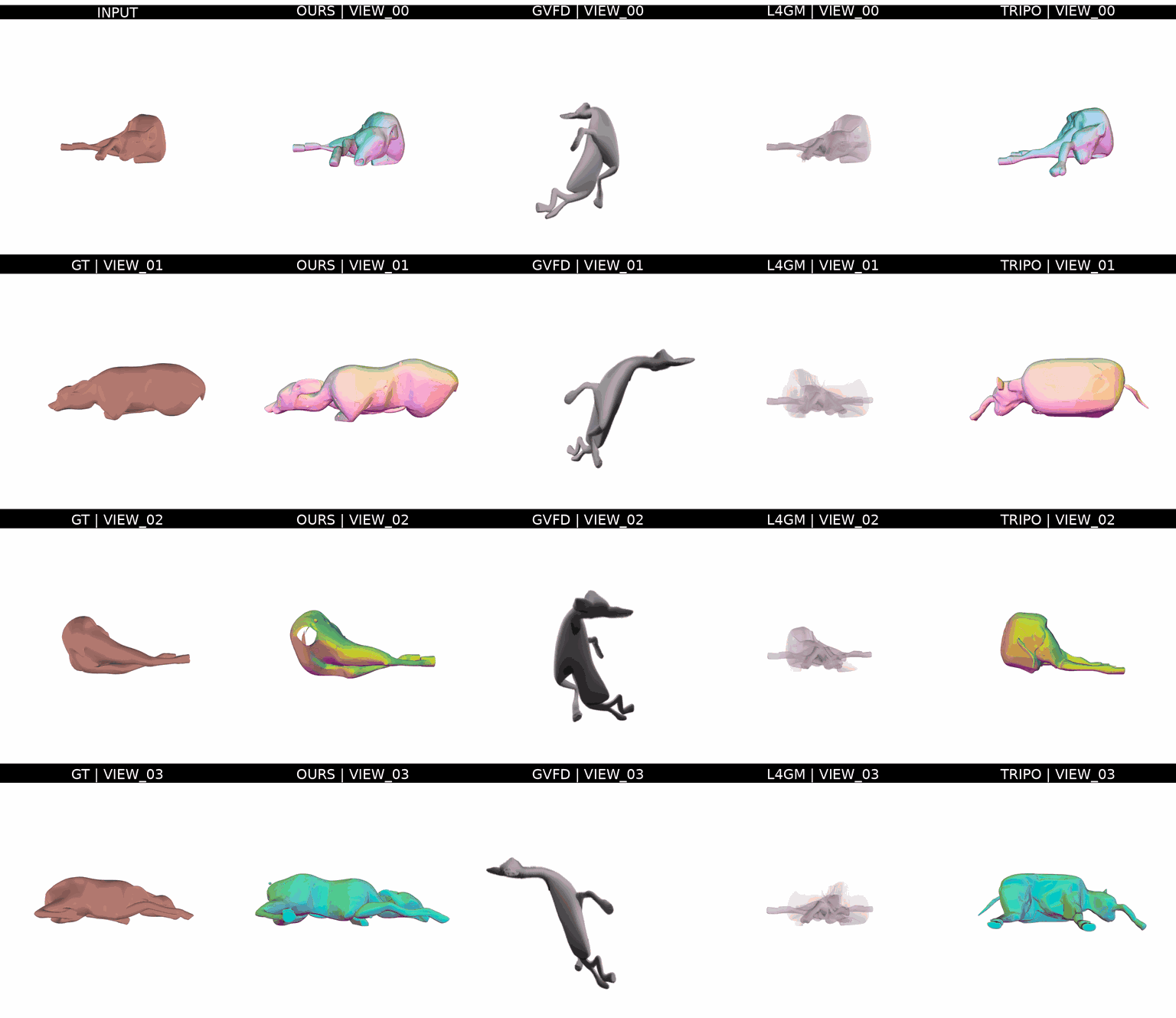



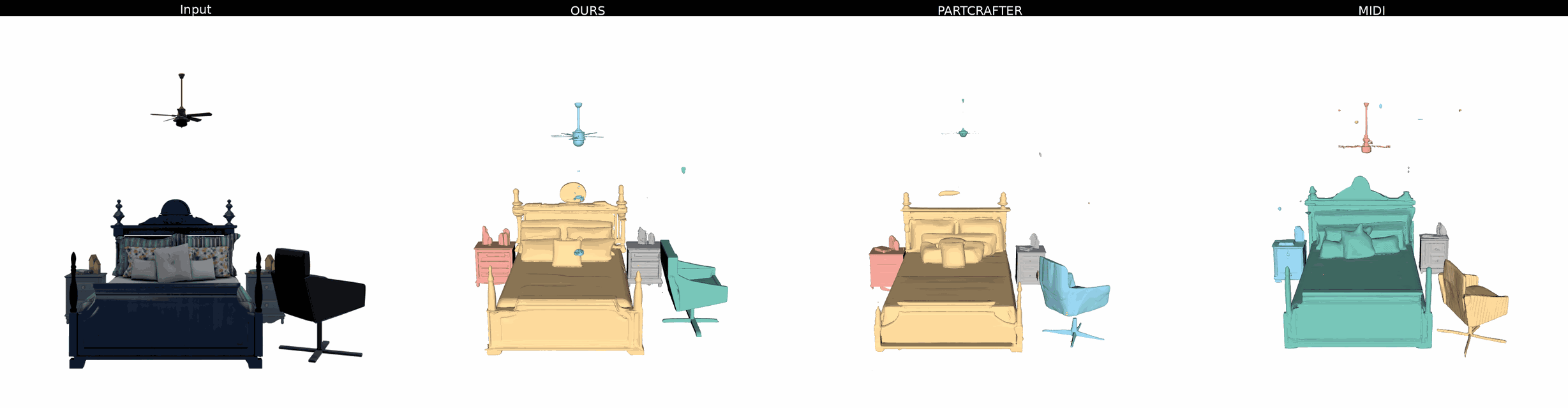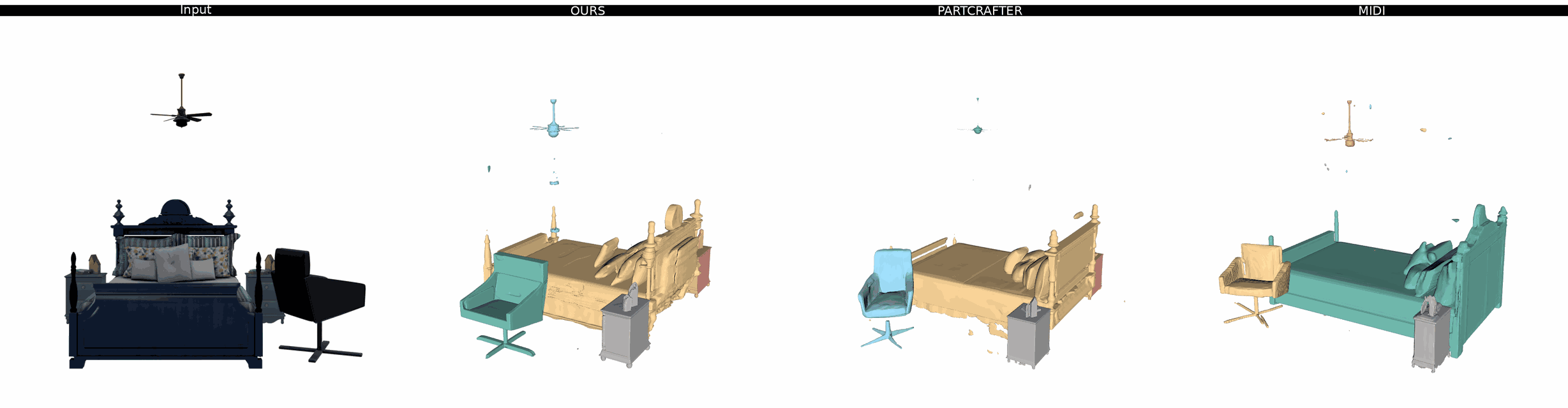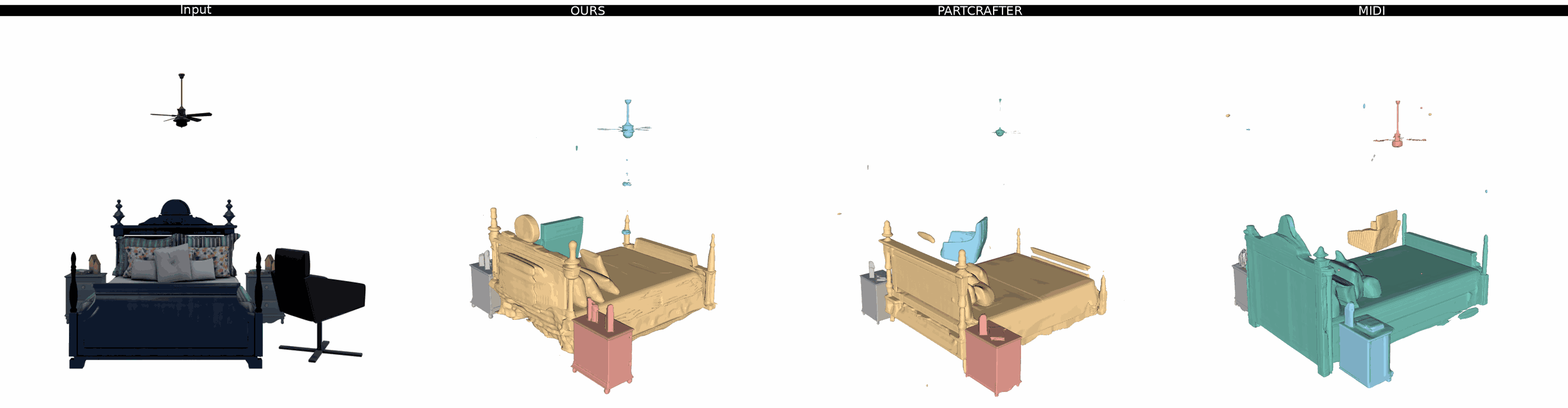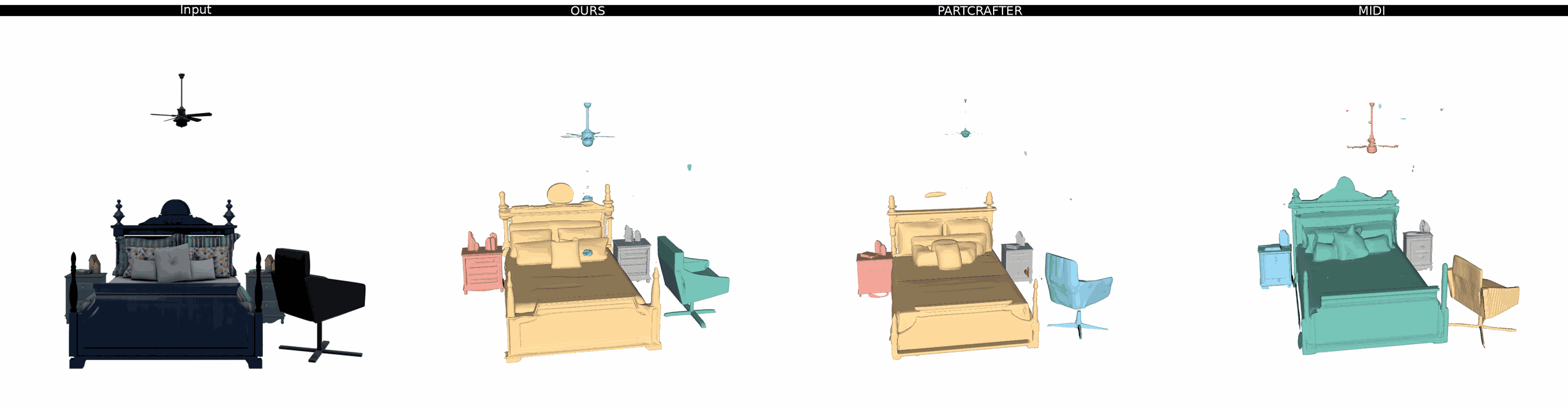
Ours
PartCrafter
MIDI
Ours
PartCrafter
MIDI
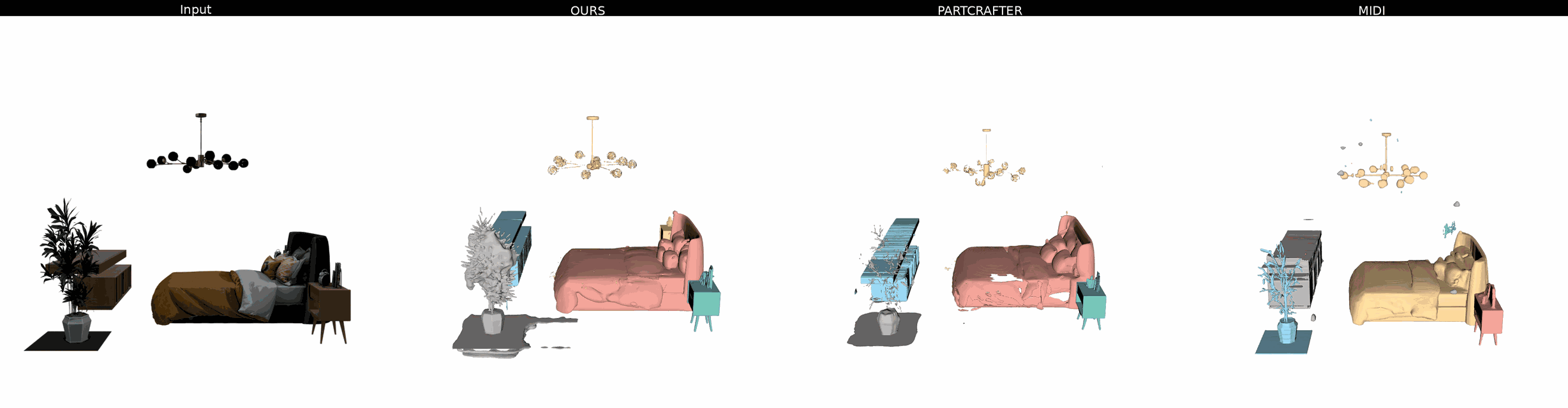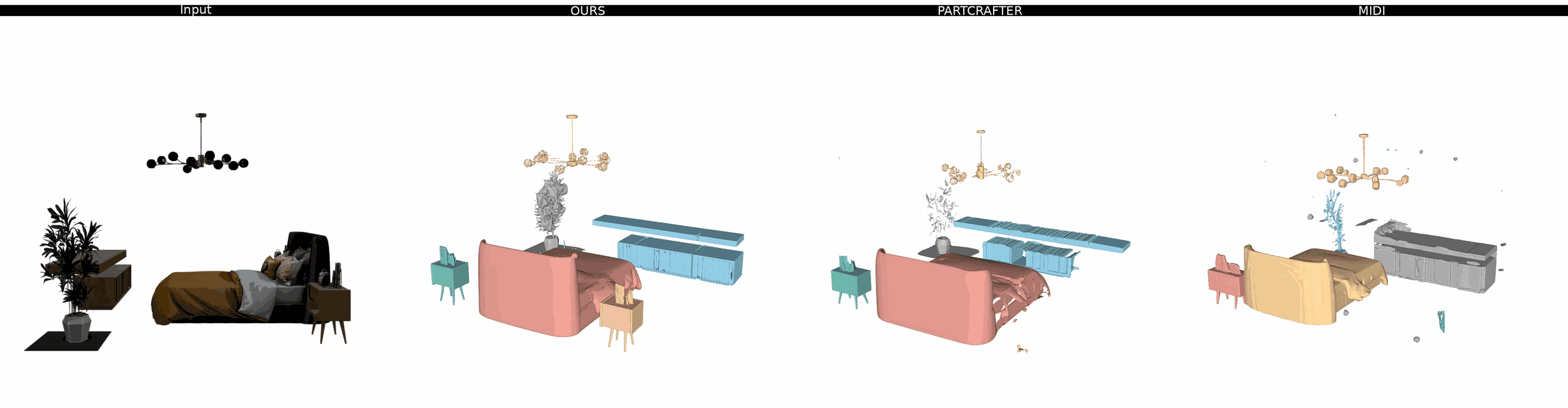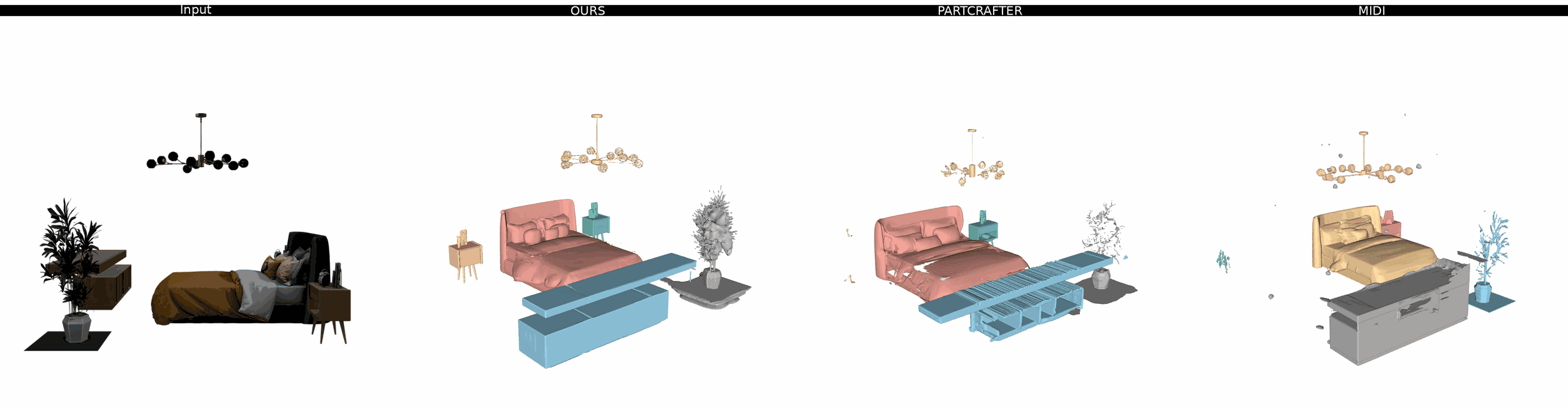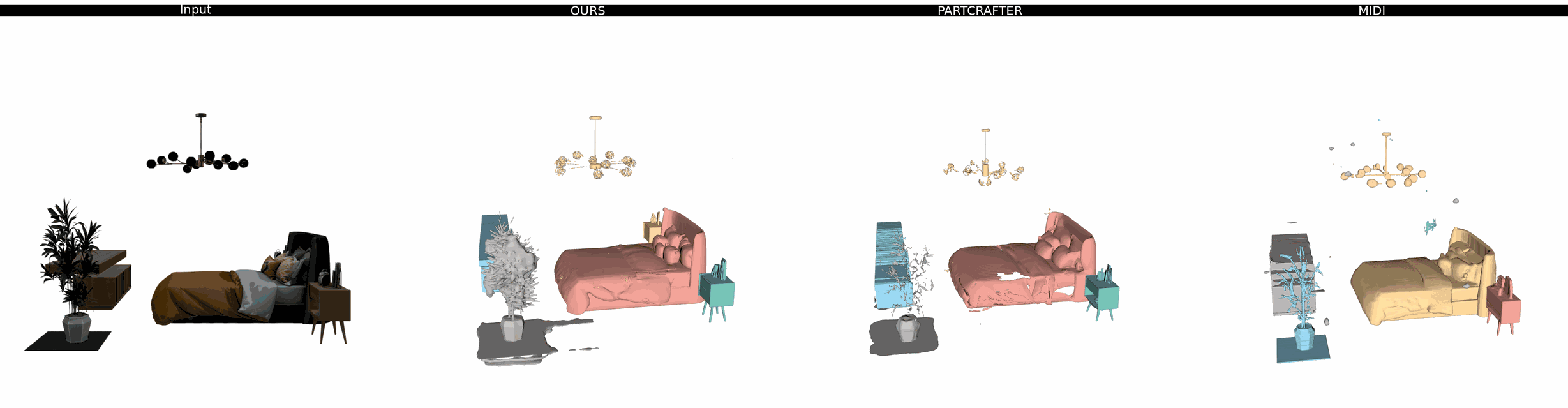
Ours
PartCrafter
MIDI
@misc{gokmen2025inferringcompositional4dscenes,
title={Inferring Compositional 4D Scenes without Ever Seeing One},
author={Ahmet Berke Gokmen and Ajad Chhatkuli and Luc Van Gool and Danda Pani Paudel},
year={2025},
eprint={2512.05272},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2512.05272},
}

